PyTorch 学习笔记(十六)
1 . gerattr、setattr 与 __getattr__、__setattr__。
result = obj.name会调用 buildin 函数getattr(obj, 'name'),如果该属性找不到,会调用obj.__getattr__('name'),没有实现__getattr__或者__getattr__也无法处理的就会raise AttributeError;obj.name = value会调用 buildin 函数setattr(obj, 'name', value),如果 obj 对象实现了__setattr__方法,setattr会直接调用obj.__setattr__('name', value)。
nn.Module 实现了自定义的 __setattr__ 函数,当执行 module.name = value 时,会在 __setattr__ 中判断 value 是否为 Parameter 或 nn.Module 对象,如果是则将这些对象加到 _parameters 和 _modules 这两个字典中,而如果是其他类型的对象,如 Variable、list、dict 等,则调用默认的操作,将这个值保存在 __dict__ 中。
Input:
1 | import torch as t |
Output:
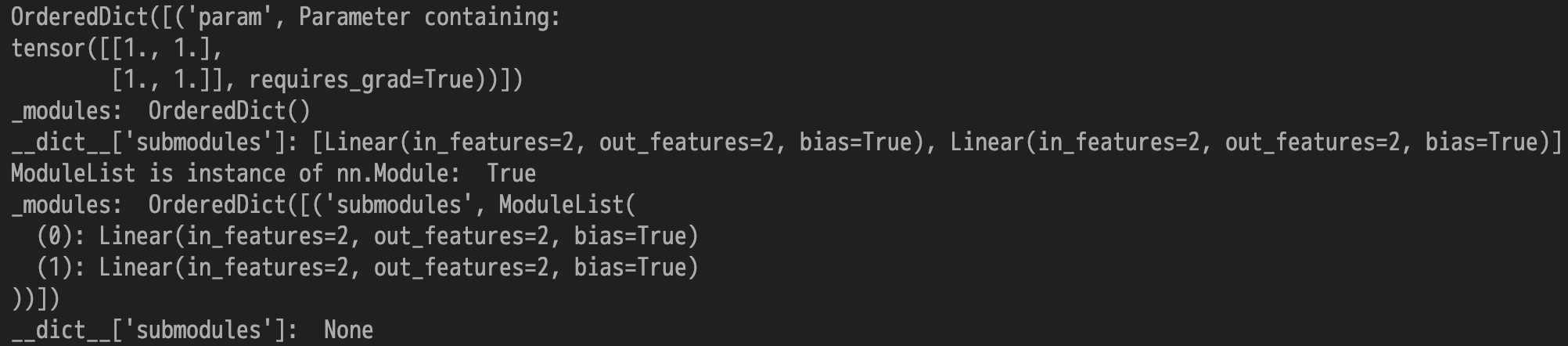
因 _modules 和 _parameters 中的 item 未保存在 dict 中,所以默认的 getattr 方法无法获取它,因而 nn.Module 实现了自定义的 __getattr__ 方法,如果默认的 getattr 无法处理,就调用自定义的 __getattr__ 方法,尝试从 _modules、_parameters 和 _buffers 这三个字典中获取。
Input:
1 | print(getattr(module, 'training')) # 等价于 module.training |
Output:

2 . 在 PyTorch 中保存模型十分简单,所有的 Module 对象都具有 state_dict() 函数,返回当前 Module 所有的状态数据,将这些状态数据保存后,下次使用模型时即可利用 model.load_state_dict() 函数将状态加载进来。
1 | # 保存模型 |
3 . 将 Module 放在 GPU 上运行只需两步:
model = model.cuda():将模型的所有参数都转存到 GPU 上;input.cuda():将输入数据也放置到 GPU 上。
如何在多个 GPU 上并行计算,PyTorch 也提供了两个函数,可实现简单高效的并行 GPU 计算:
nn.parallel.data_parallel(module, inputs, device_ids=None, output_device=None, dim=0, module_kwargs=None)class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
二者的参数十分相似,通过 device_ids 参数可以指定在哪些 GPU 上进行优化,output_device 指定输出到哪个 GPU 上,唯一的不同就在于前者直接利用多GPU并行计算得出结果,而后者返回一个新的 Module,能够自动在多GPU上进行并行计算。
1 | # method1 |
笔记来源:《pytorch-book》